
AI Agents in Healthcare and Education: Where the Real Complexity Lives

Real estate and BFSI were the obvious first markets for AI calling agents. High call volumes, structured conversation flows, clear conversion events — a site visit booked, an EMI paid. The AI fits the workflow without much creative interpretation.
Healthcare and education are different. The conversations are less transactional. A parent asking about admissions has questions that don't map neatly onto a decision tree. A patient calling after discharge might mention something in passing that a trained clinician would flag immediately. The cost of getting it wrong isn't a missed sale. It can be a missed diagnosis or a family that chose the wrong institution for their child.
These sectors are where AI agents meet their real constraints. And where the deployments that are running in production have had to think harder about architecture than anyone else.
Healthcare: the follow-up gap nobody is filling
India discharges millions of patients from hospitals every year. A fraction of them get a structured follow-up call. Not because nobody cares — because there aren't enough people to make the calls.
A typical 300-bed hospital with 15,000 monthly discharges would need a dedicated team of 8–10 staff just to run 3-day and 7-day follow-up calls at scale. Most outpatient departments have 1–2 people doing this, which means they call the patients they remember or the ones flagged manually.
The patients nobody calls are the ones who don't know they should be worried.
AI voice agents running structured post-discharge follow-up are solving a volume problem, not replacing clinical judgment. The scope is narrow and intentional:
| Task | AI agent handles | Escalates to human |
|---|---|---|
| 3-day post-discharge check-in | Yes — structured symptom collection | If symptom flags above threshold |
| Medication refill reminder | Yes — outbound call + WhatsApp | If patient reports adverse effect |
| Appointment reminder and confirmation | Yes — with rescheduling | If complex scheduling conflict |
| Diagnostic result notification | No — human-only | Always |
| Clinical advice or interpretation | No | Always |
| Emotional distress or crisis | No | Immediate escalation |
That last row matters. An AI agent that encounters a patient expressing distress — grief, fear, suicidal ideation — must escalate immediately, not attempt to manage the conversation. This is not a product limitation. It's the right design.
Symptom collection: the hardest NLU problem in healthcare AI
Structured symptom collection sounds simple until you hear how patients actually describe what they're experiencing.
A patient discharged after cardiac surgery might say:
- "Seene mein thoda sa dard hai" (chest, mild pain)
- "Breathlessness ho rahi hai thodi thodi" (intermittent breathlessness)
- "Bas thak jaata hoon jaldi" (fatigue)
These are three different utterances describing a pattern that a cardiologist would immediately recognize as potentially serious. An AI agent that parses these as three separate low-severity observations and marks the call complete has failed at the actual job.
The right architecture uses structured clinical entity extraction with severity scoring, not simple intent matching:
from dataclasses import dataclass
from typing import List, Optional
import asyncio
@dataclass
class SymptomObservation:
raw_text: str
normalized_symptom: str # SNOMED-mapped or internal codeset
body_location: Optional[str]
severity: str # mild / moderate / severe / unstated
onset: Optional[str] # acute / gradual / post-procedure
language_detected: str
confidence: float
@dataclass
class FollowUpAssessment:
patient_id: str
call_id: str
observations: List[SymptomObservation]
aggregate_risk_score: float # 0.0 – 1.0
escalation_required: bool
escalation_reason: Optional[str]
next_action: str # "schedule_callback" | "alert_clinician" | "routine_follow_up"
async def assess_followup_call(
transcript: str,
patient_context: dict,
procedure_code: str
) -> FollowUpAssessment:
# Step 1: Extract symptoms from transcript
symptoms = await extract_clinical_entities(
text=transcript,
language=patient_context["preferred_language"],
procedure_context=procedure_code
)
# Step 2: Score against procedure-specific risk matrix
risk = await score_symptom_cluster(
symptoms=symptoms,
procedure=procedure_code,
days_post_discharge=patient_context["days_since_discharge"],
comorbidities=patient_context["comorbidities"]
)
# Step 3: Hard escalation rules override model output
force_escalate = any([
any(s.normalized_symptom in IMMEDIATE_ESCALATION_SYMPTOMS for s in symptoms),
risk.score > ESCALATION_THRESHOLD, # typically 0.65 for post-cardiac
patient_context["age"] > 70 and risk.score > 0.45
])
return FollowUpAssessment(
patient_id=patient_context["id"],
call_id=generate_call_id(),
observations=symptoms,
aggregate_risk_score=risk.score,
escalation_required=force_escalate,
escalation_reason=risk.primary_driver if force_escalate else None,
next_action=determine_next_action(risk, force_escalate)
)
IMMEDIATE_ESCALATION_SYMPTOMS is a hard-coded list — chest pain post-cardiac, sudden severe headache post-neuro, signs of infection post-surgical. These are not model decisions. They're rules. The model doesn't get to weigh these against context. If the symptom appears, escalation fires.
This is an important design principle for healthcare AI: the LLM handles language understanding. Rules handle clinical safety decisions. The two layers should be architecturally separate, not merged into a single prompt.
Multilingual symptom NLU: where most systems break
Clinical NLU is already hard. Clinical NLU across 12 Indian languages, with code-mixing, is substantially harder.
The specific failure modes in vernacular clinical NLU:
1. Symptom metaphors that don't translate
"Seene mein bojh sa lagta hai" (chest feels heavy) is a common Hindi description of chest discomfort. A model trained predominantly on English clinical text may classify this as fatigue or psychological rather than a potential cardiac symptom. The metaphor needs culture-specific training data.
2. Lay terms vs. clinical terms
A patient won't say "dyspnea." They'll say "saans phoolti hai" or "dama jaisi takleef" depending on region. The entity extraction model needs a lay-term → clinical concept mapping that's language and dialect-specific, not just a translation of the English medical lexicon.
3. Negation handling in code-mixed speech
"Dard nahi tha, but thodi jalan thi" — "there was no pain, but there was some burning." Negation in code-mixed Hindi-English has grammatical patterns different from either parent language. Standard dependency parsing trained on monolingual corpora gets negation wrong here with meaningful frequency.
# Example: negation handling in code-mixed clinical transcript
test_utterance = "bukhar nahi hai but body mein dard hai"
# Naive extraction (wrong):
# → entities: [fever, body pain]
# → misses negation on fever
# Correct extraction with code-mixed negation parser:
parsed = await clinical_ner.extract(
text=test_utterance,
language="hi-IN-codemixed",
negation_aware=True
)
# → entities: [
# {symptom: "fever", negated: True},
# {symptom: "body pain", negated: False, severity: "unstated"}
# ]
The negation_aware flag triggers a separate parsing pass with a negation scope model trained on code-mixed clinical text. On monolingual Hindi and English, the standard NER handles negation acceptably. On code-mixed input, it doesn't.

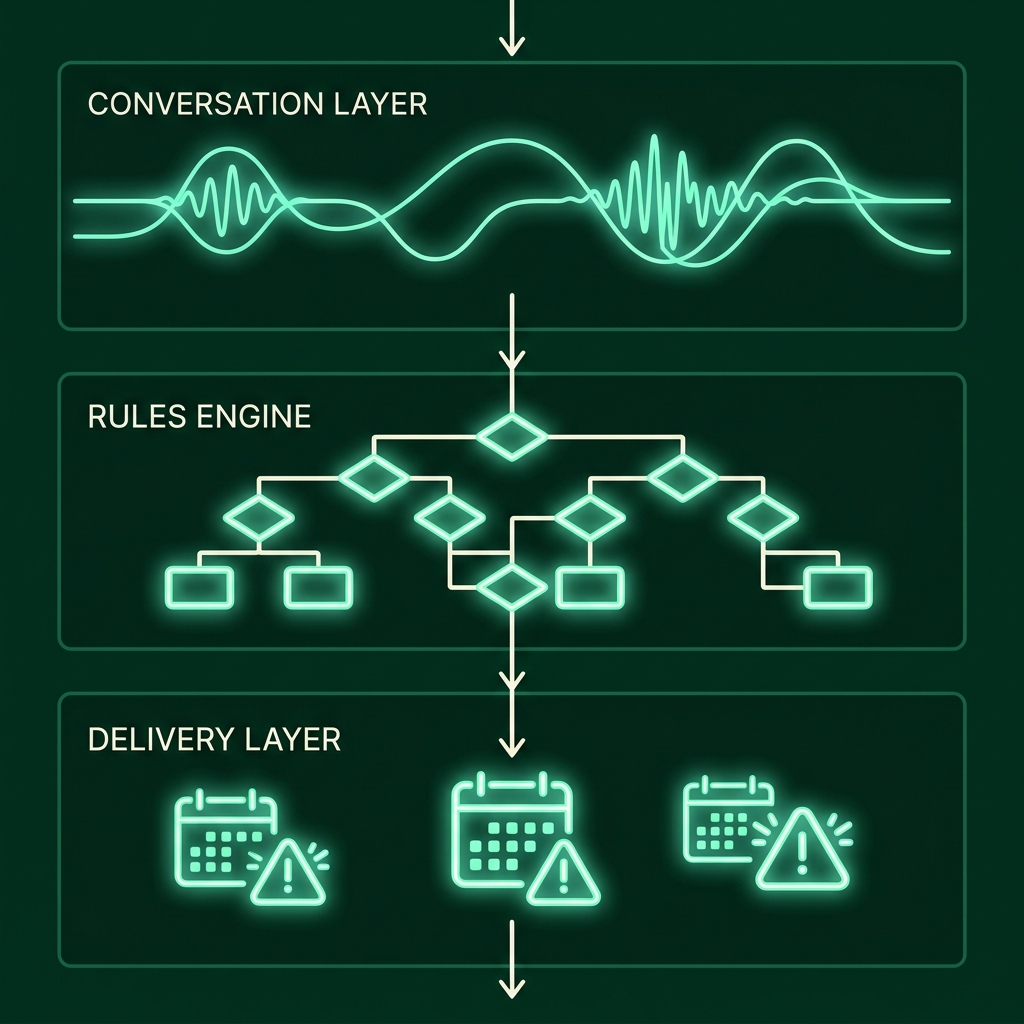
The guardrails architecture for clinical deployments
Healthcare is the domain where prompt-based guardrails are not enough. "Don't give medical advice" in a system prompt is not a safety guarantee. It's a suggestion that the model follows until the conversation structure makes deviation feel statistically appropriate.
The production architecture separates safety-critical decisions from the LLM entirely:
┌────────────────────────────────────────────────┐
│ CONVERSATION LAYER (LLM) │
│ Language understanding · Symptom collection │
│ Empathy framing · Language switching │
│ Handles: "what happened after discharge?" │
└──────────────────────┬─────────────────────────┘
│ structured output only
│ (symptoms, severity, flags)
┌──────────────────────▼─────────────────────────┐
│ CLINICAL RULES ENGINE (deterministic) │
│ Hard escalation triggers (no model override) │
│ Banned response types (clinical advice, Dx) │
│ Mandatory disclaimers on specific topics │
│ Audit log of every decision │
└──────────────────────┬─────────────────────────┘
│ approved response + action
┌──────────────────────▼─────────────────────────┐
│ RESPONSE DELIVERY LAYER │
│ Voice synthesis · WhatsApp follow-up │
│ CRM write · Clinician alert if escalated │
└────────────────────────────────────────────────┘
The LLM doesn't talk directly to the patient. It talks to the rules engine. The rules engine talks to the patient. This means every clinical safety check happens in deterministic code, not probabilistic inference. You can audit it. You can test it exhaustively. You can prove to a regulator that it behaves correctly on a specific input.
This adds latency — roughly 80–150ms for the rules engine pass. That's acceptable for a healthcare follow-up call where the conversation pace is gentler than a sales qualification call.
Education: the admissions funnel as a language problem
A parent calling a school or college about admissions in India is often doing something complicated. They're evaluating an institution that will shape their child's next several years, asking questions in their native language, and trying to make sense of fee structures, scholarship criteria, hostel availability, and placement records — often in a single call.
The institution's admissions team is typically 5–15 people handling thousands of enquiries across a campaign season. The calls that happen at 8pm when the team has gone home don't get answered. The follow-up calls that should happen 3 days after an enquiry — they happen to maybe 40% of leads if it's a good week.
AI admissions agents running on telephony + WhatsApp address a specific part of this: first response, Q&A on documented information, and scheduling campus visits.
The AI handles volume. The counsellor handles conversion. This is the division that makes the economics work — a 15-person admissions team can now have their best people focused on the parents who've already visited, while the AI manages the top of the funnel.
What the knowledge base architecture looks like
The quality of an admissions AI agent is directly proportional to the quality of its knowledge base. An agent grounded on a well-structured, current, institution-specific knowledge base answers correctly. An agent improvising from general training data makes up fee structures and placement statistics.
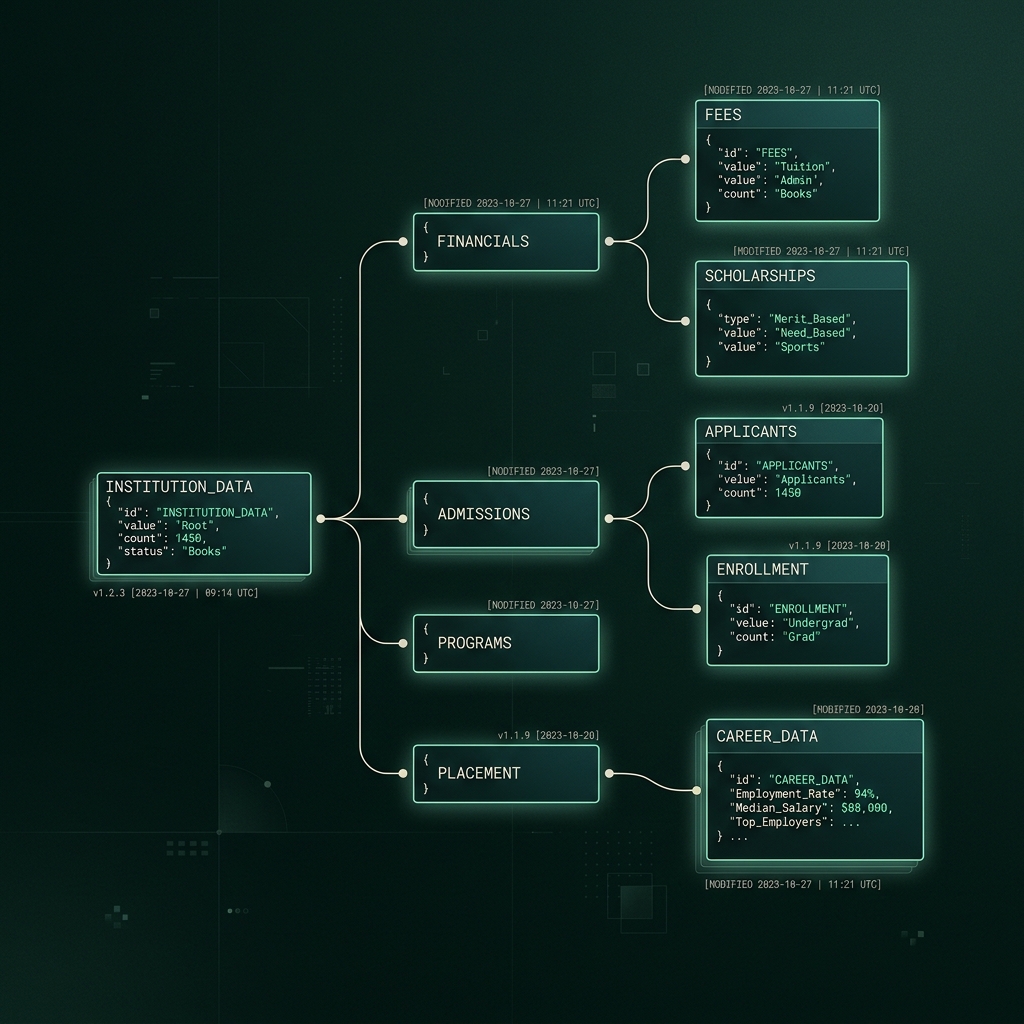
# Knowledge base structure for an educational institution
INSTITUTION_KB = {
"programs": [
{
"name": "B.Tech Computer Science",
"duration": "4 years",
"seats_total": 120,
"seats_available_2025": 44,
"annual_fee_inr": 185000,
"scholarship_criteria": [
{"type": "merit", "cutoff_percentile": 90, "discount_pct": 30},
{"type": "sibling", "discount_pct": 10},
{"type": "state_rank", "cutoff": 500, "discount_pct": 20}
],
"hostel_available": True,
"hostel_fee_annual": 72000,
"placement_2024": {
"placement_pct": 89,
"avg_package_lpa": 7.4,
"top_recruiters": ["Infosys", "TCS", "Wipro", "Razorpay"]
}
}
],
"campus": {
"location": "Bengaluru, Electronic City Phase 2",
"visit_slots": ["Mon-Sat 10am-5pm", "Sun by appointment"],
"transport": "Shuttle from Hebbagodi metro station"
},
"admissions": {
"process": ["Online application", "Document verification", "Merit list", "Counselling"],
"documents_required": ["10th marksheet", "12th marksheet", "Aadhaar", "Passport photo"],
"last_date_2025": "2025-06-30",
"contact_email": "admissions@institution.edu",
"contact_phone": "+91-XXXXXXXXXX"
}
}
The agent reasons over this structured data, not general knowledge. If a parent asks "fees kitni hai?" the agent returns 185000 from annual_fee_inr, not a hallucinated range. If they ask about placements, the agent cites 89% and 7.4 LPA from the 2024 data — and, critically, says "2024 data" rather than presenting it as a current guarantee.
The knowledge base needs version control and update discipline. Scholarship criteria that changed after April shouldn't still be what the agent quotes in June.
# Knowledge base versioning
kb_entry = {
"field": "scholarship_criteria.merit.cutoff_percentile",
"value": 85, # updated from 90
"effective_date": "2025-04-01",
"updated_by": "admissions_coordinator",
"previous_value": 90,
"agent_update_deployed": "2025-04-01T09:00:00Z"
}
The agent_update_deployed timestamp matters for audit purposes. If a parent received incorrect information before the update, you need to know what the agent was told at that point in time.
Language switching in counselling conversations
Admissions calls frequently switch languages mid-conversation. A parent might start in English to sound formal, then switch to Kannada or Telugu when asking about something personal — hostel safety, food, how students from their community have fared.
The language switch is often not just linguistic. It signals a shift in what the parent is really asking. The AI agent needs to match this.
async def handle_utterance(utterance: str, session: SessionContext) -> AgentResponse:
# Detect current utterance language
detected_lang = await language_detector.detect(utterance)
# Update session language preference on sustained switch
if detected_lang != session.current_language:
switch_confidence = await language_detector.switch_confidence(
history=session.last_5_utterances,
new_lang=detected_lang
)
if switch_confidence > 0.75:
session.current_language = detected_lang
session.language_switch_count += 1
# Generate response in detected language
response = await reasoning_layer.generate(
utterance=utterance,
context=session.to_context_dict(),
response_language=detected_lang,
knowledge_base=INSTITUTION_KB,
persona="warm_counsellor" # vs "efficient_qualifier" for sales
)
# Adapt TTS voice to match language
voice_config = VOICE_MAP.get(detected_lang, VOICE_MAP["en-IN"])
return AgentResponse(
text=response.content,
language=detected_lang,
voice=voice_config,
follow_up_action=response.suggested_action
)
VOICE_MAP = {
"hi-IN": "aarya-hi",
"kn-IN": "priya-kn",
"te-IN": "kavya-te",
"ta-IN": "meera-ta",
"en-IN": "nora-en",
"mr-IN": "sneha-mr"
}
The switch_confidence check before updating the session language prevents a single code-mixed word from resetting the conversation language. If a parent says "ya, fees ke baare mein bata" — that's Hinglish, not a switch to Hindi. The sustained switch detection looks at the last 5 utterances before committing to a language change.
The persona parameter is worth noting. A healthcare follow-up call uses a different conversational register than an admissions counselling call. Warm and unhurried for both — but the vocabulary, the sentence length, the probing questions are different. These are separate persona configurations, not separate models.
What the production numbers look like
These figures come from deployments running in India across real estate, education, and healthcare — not curated demos.
| Metric | Healthcare (post-discharge) | Education (admissions) |
|---|---|---|
| First response time (new enquiry / follow-up trigger) | Automated, scheduled < 2 min | < 60 seconds |
| Call completion rate | 71% | 68% |
| Escalation accuracy (right calls escalated) | 91% | 84% |
| Language switch handling accuracy | 88% | 83% |
| Post-call CRM / EMR completeness | 94% | 91% |
| CSAT vs human-handled equivalent | –0.2 pts (within margin) | –0.3 pts |
| Cost per completed interaction | 60–70% lower than human-handled | 55–65% lower |
The CSAT numbers deserve comment. AI-handled follow-up calls in healthcare score 0.2 points lower than human-handled calls on a 5-point scale. That gap is real. For routine follow-ups — medication reminders, appointment confirmations, structured symptom checks — it's a gap patients accept. For emotionally charged conversations, it's the reason escalation rules have to fire early.
The failure modes nobody puts in the brochure

Over-reliance on the AI for complex questions it shouldn't be answering
When an institution deploys an admissions AI and doesn't clearly define what the agent should decline to answer, the agent starts answering everything. Questions about which professor teaches a specific course. Whether the hostel has a specific type of food. What the campus feels like. These are questions the AI will answer with something plausible — and plausible is not the same as accurate.
Define the out-of-scope list explicitly. "I don't have that information, but your counsellor can answer this when you visit" is the right answer to 20% of admissions questions. An agent that never says this is improvising.
Symptom normalization errors on vernacular input
Clinical entity extraction models trained on English medical corpora perform acceptably on English input. They degrade on Hindi, and they degrade further on regional languages. A chest pain descriptor in Odia that doesn't map cleanly to the training vocabulary may get classified as musculoskeletal rather than cardiac.
This is the most serious failure mode in healthcare AI and the least discussed one. The fix is language-specific clinical fine-tuning on real patient transcripts — not just translation of English training data, which introduces its own artifacts.
Knowledge base staleness
Fees change. Scholarship deadlines shift. Hostel seat availability fluctuates. An admissions AI running on January's knowledge base in June is quoting wrong numbers. Institutions that deploy AI without a knowledge base update process will have the AI confidently misquoting fees that changed three months ago.
Consent fatigue and its effect on data quality
Every follow-up call in healthcare needs some form of consent for data collection. When the consent prompt is long, legalistic, or repeated too often, patients start skipping it or declining. This creates gaps in the follow-up data. Institutions that design consent interactions poorly end up with patchy records — worse than no AI at all, because the gaps look like negative outcomes rather than consent declines.
What's coming next in these sectors
Ambient clinical documentation — AI listening during in-person consultations and generating structured notes — is being piloted. It's a harder problem than follow-up calls because the acoustic environment is more complex and the clinical responsibility is higher.
In education, AI agents that can assess student learning gaps through conversation (not just answer admissions questions) are being developed. This crosses into pedagogy in ways that telephony agents don't.
Both trajectories involve more capability and more responsibility. The architecture principles that matter now — hard rules for safety-critical decisions, transparent escalation, explicit knowledge base grounding — don't become less important as capability increases. They become more important.
Part of the Arvo.ai technical blog series on conversation-led agentic AI. www.auum.in